 400 606 5709
体验 DEMO
400 606 5709
体验 DEMO
400 606 5709
体验 DEMO
400 606 5709
体验 DEMO
2025年12月17日 • 作者:DataPipeline



近年来,人社领域一体化平台建设持续推进,省级层面逐步完成了数据集中与系统统一。但对市级人社部门而言,真正的挑战并不在于“是否有数据”,而在于如何把省级数据能力真正用到本地业务现场,支撑就业服务的高频办理和实时运行。
在这一背景下,西部某市人社部门以就业服务为切入点,围绕市级业务经办与运行监测的实际需求,探索将省级数据体系与市级业务系统深度衔接,推动数据从“集中存储”走向“现场可用”,为市级公共就业服务构建起可直接支撑业务运行的实时数据体系。
随着公共就业服务对时效性和准确性要求不断提高,该地人社部门逐步意识到,就业治理能力的提升,关键在于是否具备覆盖登记、申报、审核、发放到统计分析等全流程的数据实时流转能力。就业数据以省级平台为源头,涉及多个系统与业务环节,一旦数据流转滞后或口径不一致,便会直接影响业务办理效率和运行判断。因此,建设一套稳定、高效的就业数据全链路实时同步体系,成为支撑市级就业服务运行的基础条件。
围绕上述需求,项目以省级人社核心业务数据库为源头,搭建起覆盖“回流—业务—决策”的三级实时数据流转体系:
· 源头回流:从省级平台中精准抽取属地就业数据,实时同步至地市级回流库,作为统一的数据中转节点。
· 业务支撑:将回流数据以秒级能力分发至生产业务库,支撑就业失业登记、补贴申领等高频业务的实时查询与经办。
· 决策驱动:同步数据至交换库,经加工处理生成统计指标,用于动态展示就业规模、结构分布等关键信息,辅助运行监测与管理决策。
基于这一体系,市级人社部门对数据平台提出了清晰要求:既要保证数据链路稳定、同步及时,又要同时服务于一线经办和运行分析等不同使用场景。
DataPipeline助力西部某市人社部门,实时数据融合平台顺利上线
为支撑上述实时数据流转体系的稳定运行,项目引入 DataPipeline 企业级实时数据融合平台,作为统一的数据融合与分发引擎。平台在不改变原有业务系统架构的前提下,适配现有数据库与技术体系,实现多源数据的实时采集、统一处理与可靠传输,为就业数据在省、市及业务系统之间的流转提供底层支撑。
在数据采集侧,平台从省级人社核心数据库中抽取属地就业数据,并以低延迟方式实时同步至地市级回流库;在数据使用侧,将回流库数据秒级分发至生产业务库,支撑 12 项高频业务的实时查询与办理,同时同步数据至交换库,通过 ETL 加工生成可直接使用的统计指标,驱动政务大屏对就业率、产业分布等 8 类核心指标的动态展示,形成从业务经办到运行分析的完整数据链路。
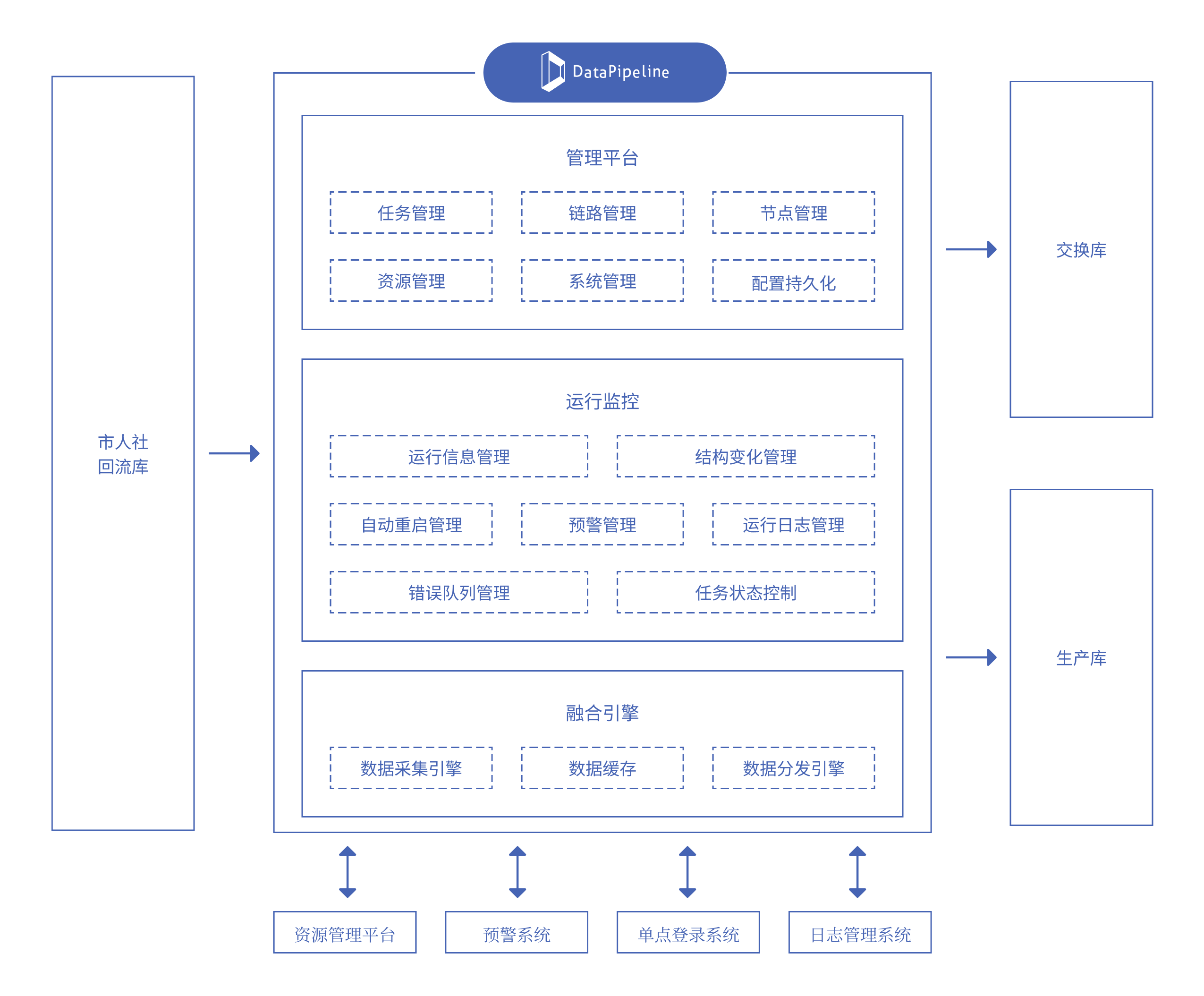
实时数据融合平台架构
▶ 高性能实时处理
平台提供 TB 级吞吐、秒级低延迟的增量处理能力,保障就业数据在多级系统间稳定、高效流转。
▶ 无代码敏捷管理
通过可视化配置方式完成数据对象映射与融合策略调整,使数据融合任务由研发驱动转为配置驱动,交付周期由周级缩短至分钟级。
▶ 极稳定高可靠
采用分布式高可用架构,结合多种容错与自动恢复机制,应对结构变化、数据异常及网络波动,保障业务连续运行。
▶ 全链路数据可观测
构建覆盖容器、应用、线程与业务层的监控体系,配合统一驾驶舱与自动化运维能力,实现任务状态可视、资源弹性可控。
平台上线后,就业数据在省、市、业务系统与决策展示之间实现稳定实时流转,支撑 3 条核心实时数据链路 持续运行,日均同步数据量超 20GB,峰值处理能力达 8MB/s 以上,跨库同步时延控制在 5–10 秒 内,稳定支撑 12 项高频业务、日均超 5 万笔服务请求 以及 8 类核心决策指标 的实时展示。
在业务层面,高频就业业务实现数据实时可查、即到即用,减少人工核对与等待时间;在技术层面,通过多级实时同步架构打通异构数据库数据链路,为平台长期稳定运行和后续扩展提供可靠基础。
面向后续建设,DataPipeline 将继续与该人社部门保持紧密合作,围绕就业服务等核心业务场景,持续优化实时数据融合能力与平台运行支撑,全力保障数据链路的稳定、安全与高效运行。随着业务需求不断演进,平台也将进一步支持更多人社领域应用场景落地,助力数据能力持续向业务现场延伸,为公共就业服务的精细化运行与长期发展提供坚实支撑。





