
 400 606 5609
体验DEMO
400 606 5609
体验DEMO
400 606 5609
体验DEMO
400 606 5609
体验DEMO

成立于1996年的中国民生银行,是一家全国性股份制商业银行,2000年、2009年先后在上海证券交易所和香港联合交易所上市,《财富》世界500强榜单企业。在行业同质竞争非常激烈的情况下,民生银行实现高速增长,这与其由上至下地坚持数字化转型策略密不可分。

“数据是银行最为重要的资产之一,是支持精细化管理、实现差异化服务、加强业务创新、提升风险分析能力的基础。工欲善其事,必先利其器。为加快支撑业务数字化转型,民生银行在原有数据体系的基础上,以业务目标为驱动,以数据应用效能为优先考虑因素,打造好用、易用的数据中台;以实时、智能分析能力为基础,通过数据与模型驱动金融产品服务创新,为业务提供立体化的快速支持,直面客户,赋能场景。DataPipeline企业级实时数据同步管道平台在民生银行的成功上线,主要是在异构数据实时同步的准确性、系统的稳定性、易用性、安全性等方面很好地满足了我们的需求,实现了民生银行企业级实时数据的采集、融合与同步,为民生银行中台战略奠定了坚实的基础。同时,该平台降低了民生银行手工开发成本,加快了实时数据价值的释放。未来双方将在更多数据管理场景进行探索,推动更多实时应用落地。”

开发环境搭建和开发语言学习难度高,涉及多种分布式技术组件,使用代码开发和组件调优难度大。
关联组件的配置文件和配置项多,作业任务环境信息和配置参数多,验证环境少,配置和环境信息出错引发投产问题风险高。
错误和异常数据难以追溯;实时任务的业务监控和任务运行状态监控相对传统应用来说比较难使用行内现有监控系统完成。
客户行为等实时数据的标准化补全并分发到各个应用系统。
业务系统的实时账户变动与指标变化传输到 GaussDB 作为实时头寸的计算依据。
实时数据加载到 Redis 作为业务实时查询使用。
主数据系统数据和数据仓库数据加载到 SequoiaDB 作为历史数据查询使用。
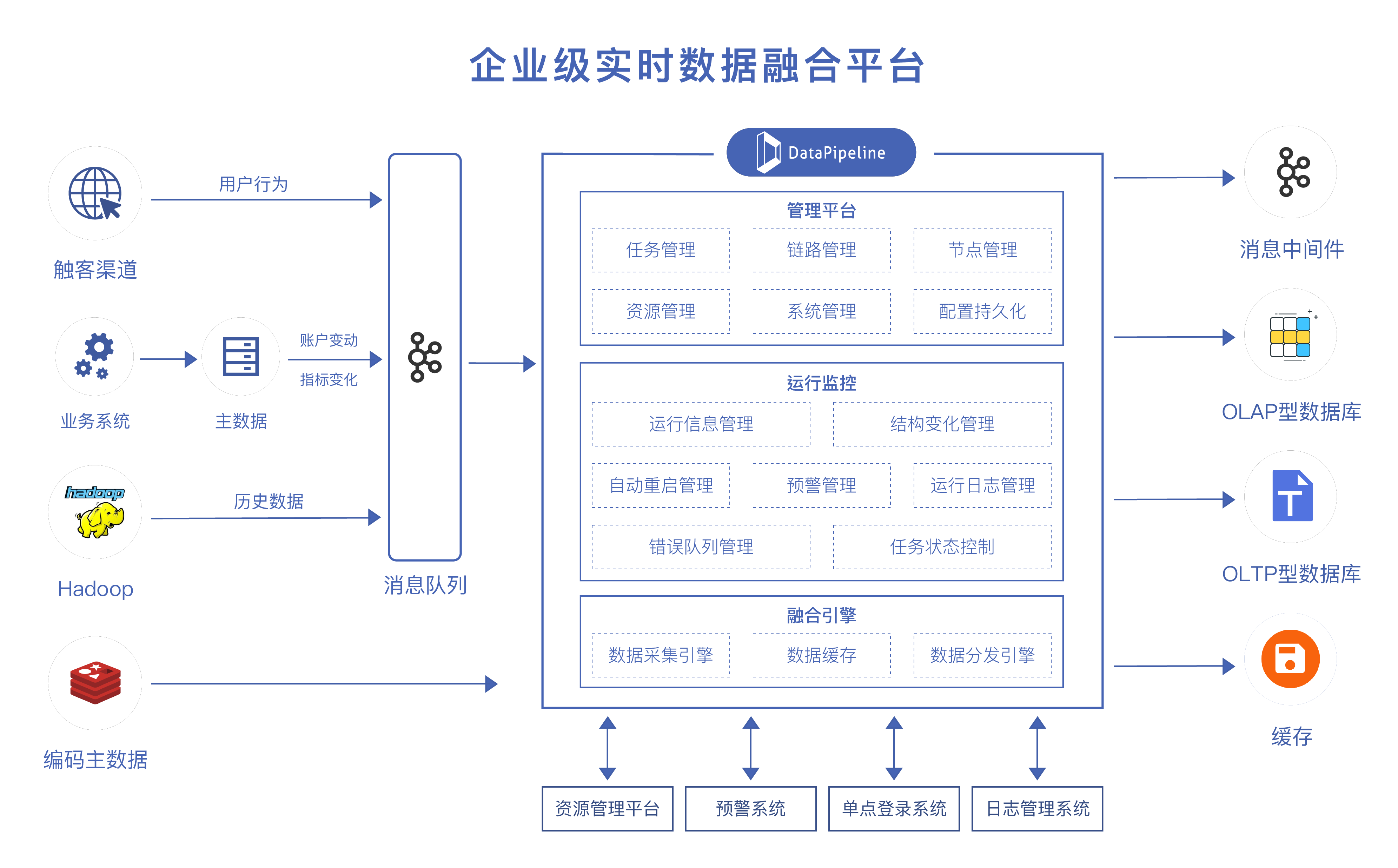

支持实时的对客、对监管的查询需求。提升数据中台查询模块的查询性能,降低存储成本。

一对多的数据下发链路可以很好地应对各种实时数据应用的场景,提高数据的复用度。

DataPipeline 简单易用,极大地加速了实时数据同步需求的开发配置和上线部署。实时数据的采集、加工均可以以配置的方式实现,一改过去项目制交付的弊端。民生银行无需再用 Spark streaming 来开发实时数据传输,降低了手工开发成本,加快了实时数据价值的释放。

