
 400 606 5609
体验DEMO
400 606 5609
体验DEMO
400 606 5609
体验DEMO
400 606 5609
体验DEMO

中泰证券股份有限公司(以下简称“中泰证券“)成立于2001年5月,是集证券、期货、基金等为一体的全国大型综合性证券控股集团(600918.SH)。公司高度重视金融科技发展,持续构建“科技牵引,全面赋能”的金融科技体系,以金融科技赋能业务发展、推动业务创新、强化支撑体系。中泰证券的数字化转型与流程管理项目入选了国务院国有重点企业管理标杆项目,也是唯一一家入选的券商,其业务线上化平均水平更是达到近90%的高水平。

“DataPipeline不仅释放了数据潜力、还优化了人力资源配置,把数据工程师和运维人员从重复劳动和不必要的开发中解放出来,有效地将有限的资源聚焦投入到能够形成差异化竞争优势的战略资产(企业用来向客户提供产品或服务的工具)建设中,极大地提升了用户的体验和满意度。同时,DataPipeline也为我司未来构建自主可控的国产创新生态体系奠定了坚实基础,满足了我们在数字化转型过程中对数据处理和管理的高效、安全需求。”

仅Oracle数据库就超过50套,此外还包括MySQL、SQL Server等不同类型数据库,不仅对团队的技术能力和管理水平提出了更高的要求,而且对整个转型过程的成功实施也构成了重大考验。
软件研发团队在开发过程中需要处理大量与业务本身无关的任务,包括编写大量网络处理、服务框架代码,以及数据库连接、缓存处理、开发和测试环境的部署等,这些工作消耗宝贵的时间和资源,严重影响团队效率。
错误和异常数据难以追溯,通过现有监控系统观测实时任务运行状态十分困难,运维工作极具难度。
支持关系型数据库、NoSQL数据库、国产数据库、数据仓库、大数据平台、云存储、API等多种数据节点类型,可自定义数据节点。
提供限制配置与策略配置两大类十余种高级配置,包括灵活的数据对象映射关系,数据融合任务的研发交付时间从按周计算降低至分钟级,大幅简化数据管理流程,显著提升敏捷性和效率。
提供一个全方位的监控体系,涵盖从容器到应用,再到线程和业务的四个级别。通过全景式驾驶舱视图,确保任务稳定运行,并通过自动化运维体系实现灵活的扩缩容,从而合理地管理和分配系统资源,实现数据流程的全面可观测性和可控性。
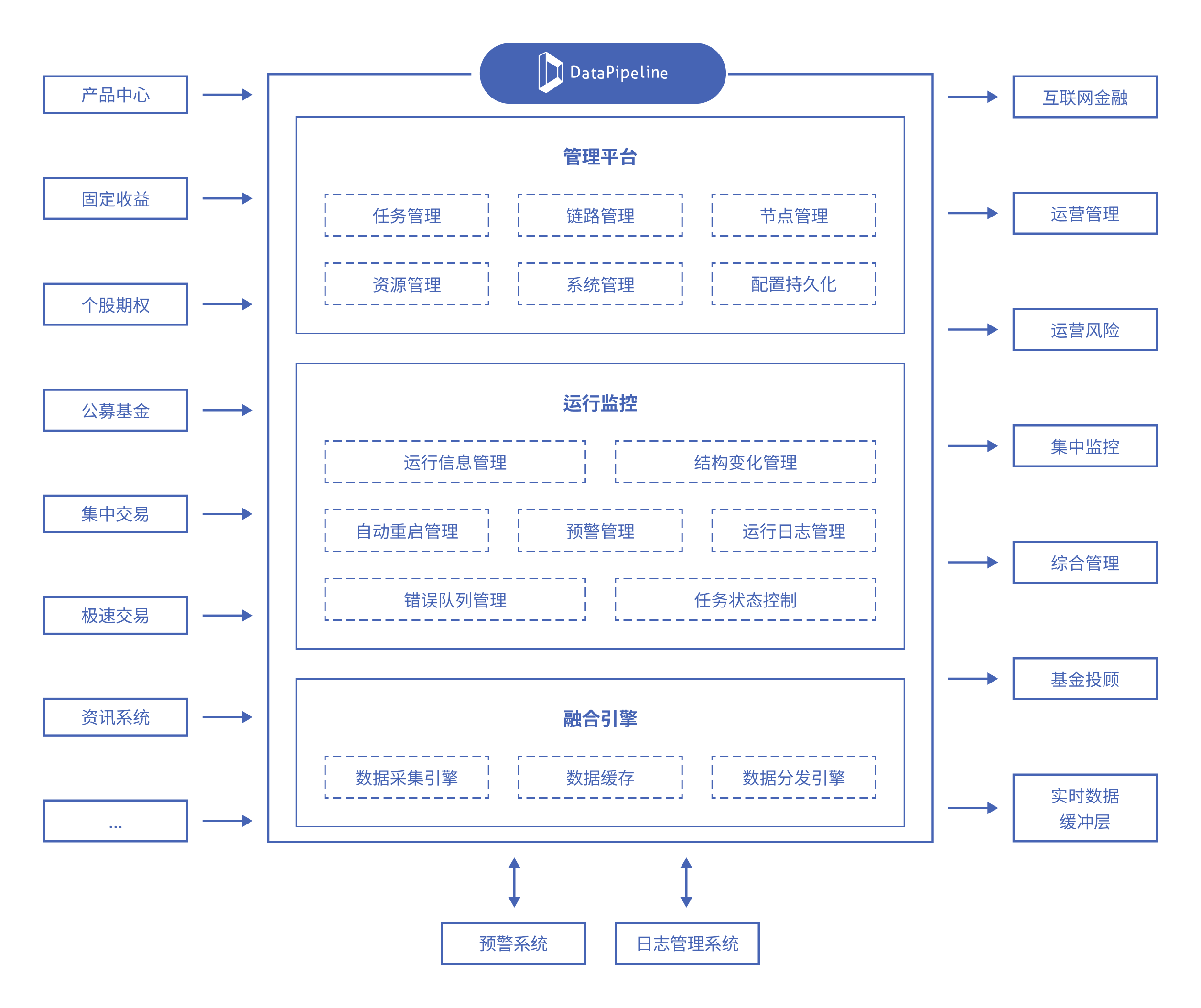
通过整合分散在不同业务系统中的数据,平台建立了一个多维度、高效的数据分析环境,为经营决策及探索数据赋能业务深入创新奠定稳固基础。

DataPipeline简单易用,极大加速了实时数据同步需求的开发配置和上线部署,实时数据的采集、加工均可以以配置的方式实现。此外,集中式的高效管理极大提升了人员效能,迅速构建数据链路,洞悉数据、任务、系统的最新动态,从而提高运维管理的工作效率和效益。

