
 400 606 5609
体验DEMO
400 606 5609
体验DEMO
400 606 5609
体验DEMO
400 606 5609
体验DEMO
DataPipeline实时数据融合引擎,可将Oracle的增量数实时同步到数据仓库、大数据平台中。
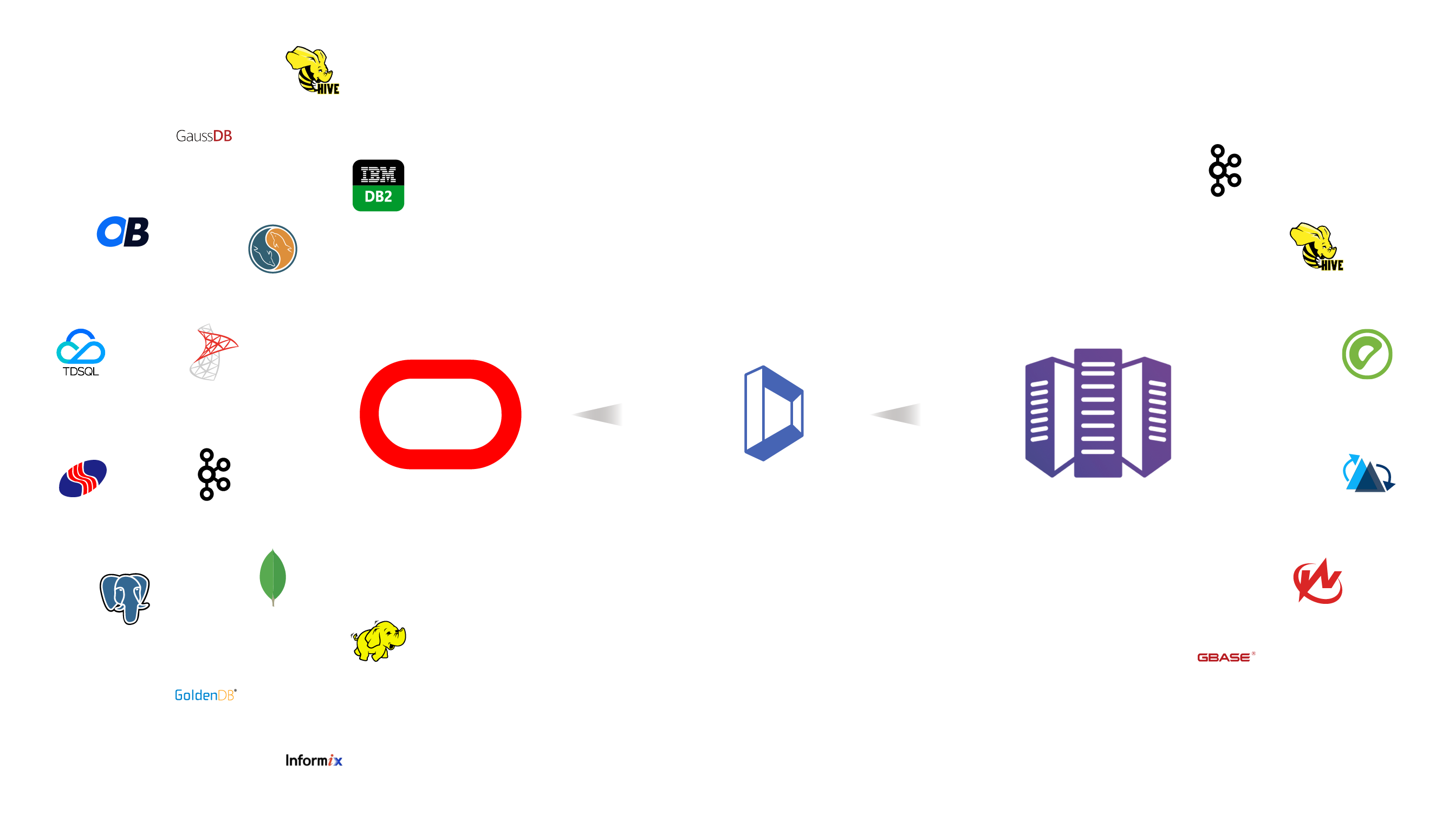

统一的平台,管理Oracle同构及异构数据节点间的实时同步与批量数据处理任务。
支持Oracle数据库数据的实时和批量数据采集,可靠地将数据多对一、一对多加载至您选择的目的地,从而加速业务分析。

基于 Oracle 数据库在线重做日志或归档重做日志(Online/Archive Redo log)获取增量数据的实时数据解析方案。具有对源端Oracle数据库低影响,写入目的地数据库低延迟的特性。

以低代码、可视化的配置方式,完成数据实时同步链路及任务的编排设置、数据融合、数据实时发布等核心功能。无需专业编程能力,业务人员、数据工程师、数据科学家等均可快速进行实时数据的应用。

通过自有增量数据采集代理读取数据库日志获取准确的增量数据,将解析的变更记录传送到数据目的地中。

支持一对多、多对一数据映射,支持异构数据之间丰富的语义映射策略。 默认语义映射规则配置,可自动化匹配,满足复杂度高、数据量大的各类数据同步场景。

作为数据任务的 “管理驾驶舱”,您可以详细了解每个数据任务同步情况。 可实时监控上下游数据变化与异常情况,确保您能够掌控激活、运行、暂停、报错、重启等数据任务状态。

DataPipeline建立在稳定高容错DataPipeline采用分布式架构,容器化部署,以保证系统业务连续性。即使出现机器故障,也能确保零数据丢失。管道中任何受影响的记录都将被保存,并实现断点续传,以确保您的分析工作流永远不会受到影响。架构上,即使传入的 Oracle 数据出现问题,也能确保零数据丢失。管道中任何受影响的记录都将被留出进行更正,以确保您的分析工作流永远不会受到影响


DataPipeline 提供与 MaxCompute 的原生集成,MaxCompute 是一个完全托管、可靠的云数据仓库,可完全自动化您的数据流。DataPipeline 可以非常轻松地在 MaxCompute 中组合不同的数据并将这些数据插入任何 BI 工具或业务应用程序
DataOps是人员、流程和技术的有机结合,用于快速向数据使用者提供可信的高质量数据。支持整个组织的协作,以推动规模化、敏捷性、速度和新的数据计划。

DataOps是人员、流程和技术的有机结合,用于快速向数据使用者提供可信的高质量数据。支持整个组织的协作,以推动规模化、敏捷性、速度和新的数据计划。

DataOps是人员、流程和技术的有机结合,用于快速向数据使用者提供可信的高质量数据。支持整个组织的协作,以推动规模化、敏捷性、速度和新的数据计划。

计划升级到现代数据堆栈?了解全球品牌如何成功迁移到现代数据堆栈并解决其关键业务数据挑战。


















