 400 606 5709
体验 DEMO
400 606 5709
体验 DEMO
400 606 5709
体验 DEMO
400 606 5709
体验 DEMO
2019年12月20日 • 作者:DataPipeline



《跨越鸿沟》的作者Geoffrey Moore曾说“没有数据,运营企业就像一个又聋又瞎的人在高速上开车一样”。数据的价值从未像现在这样被企业重视,IDC预估,到2020年,全世界会有44万亿G数据,每一个世界500强的CEO和独角兽创业公司的创始人都在思考并实践如何能用数据支持、改造、创新业务,以获得新的增长。
一、2019年大数据发展的两个趋势
就即将过去的2019年而言,在大数据领域,我们关注到有以下两个发展趋势:
一是客户更加关注数据驱动的应用,目前大家建设的思路较之前更加清晰,而且更加务实。以大数据或者人工智能为例,以往大家更多思考的是如何找到新技术在企业的落脚点,而今年随着与业务的更多结合,新技术的发展速度会相对快一些。
另外一个趋势是对速度的追求,当业务部门希望使用数据来辅助决策或者创造新的商业模式时,通常有两个时效性的要求:一是满足数据需求的速度,二是对于所需数据的延迟性。因为业务创新的关键点在于能否快速满足市场需求,不仅需要用数据快速测算市场规模,更需要在时间窗口打开的时机内提供相应的产品和服务从而占领市场。而这一过程越来越受数据供给速度及时效性的影响,例如银行业的实时头寸和实时风控系统,零售业的实时营销和互联网业务,工业界的柔性制造,都是业务创新对需求满足速度和低延迟要求非常高的典型。

以某地产企业为例,最近两个业务系统因业务开展需进行数据交互,供应商数据同步报价3人天。按照新数据同步建设标准规范,使用DataPipeline进行数据同步,配置任务仅花3分钟左右即完成。总体来说,大多数企业的数据部门在数据时效性的满足上是捉襟见肘的。
二、从建设到运转数据平台,企业还有一段路要走
尽管越来越多的人认同数据是极为重要的资产,但往往在推进落地的过程中容易陷入高投入慢节奏的怪圈。 投入产出比不清晰,多数项目半途夭折,已经成为多数企业在数据管理方面不可言说的痛。
过去一年,随着跟不同行业的客户进行深入交流,发现大家对数据融合的关注度急速提升。大家达成的共识是,如果想要最大化挖掘数据价值,仅构建一个数据平台是远远不够的。目前已经有许多企业构建了大数据平台,实际上却没有将其业务系统中的业务数据放在平台中,这对于达成目标而言,只走了一半距离。若要发挥数据的价值,还需像经营公司一样精细化地经营数据。问题看似简单,但很少有企业能在深入思考后得出严谨的回答。导致目前在使用数据的过程中存在“多、乱、慢、差”等情况,严重降低和阻碍了数据发挥作用的价值与效率。
若想实现精细化运营,就不得不迎接种种难题。当前,拥有几百上千个内外部数据源的组织越来越多,其中包括各种业务、流程、客户数据,结构化、半结构化、非结构化数据。如果再考虑到未来5G和区块链带来的应用级影响,将又会是一种难以言说的痛。
在这种复杂异构的背景下,企业一方面缺少高效整合、对外快速提供数据的方法和工具,另一方面更缺失能从这些数据中寻找规律,发掘价值的人才和文化,因此让理解、整合数据变得雪上加霜。而这恰恰是所有数据使用的起点,所以,建立数据中心只是第一步,接下来还需将批量或实时数据放在平台中,再快速将数据从平台中提供出去,供上下游使用。

同时文化、流程和工具也是帮助公司推动数据价值落地,完成数字化业务转型不可或缺的考量点。在这样的大环境下,我们看到一个机会,一种变革,它包括了:
1)使用数据时,责权清晰的组织架构和规则流程,即DataOps理念,使数据思维在组织内深入人心;
2)将自动化、智能化的现代基础设施与数据管理体系组合起来赋能企业中的每一个人。用自上而下的信任和管控激发自下而上的自主和创新,从而打破数据组因长期过载而制约企业发展的局面。
三、2020年,将从商业智能转向关注数据应用
关于数据使用,可能最早在数据分析领域应用的比较多,但业务部门很快意识到数据用来做BI分析只是其中一部分应用场景,如果能提供数据服务API给到其他业务部门或者是企业客户,就可以创造新的业务和商业模式。
为此,在2020年这些实时数据或者数据融合将走向应用层,走向数据应用。目前已经有许多客户启动了相关业务,从数据着手去改造业务思路,这在2020年将会进一步铺开。
针对这点,可能互联网公司做得比较好,但是很多大型企业在处理数字化转型时,比较缺乏这种着力点。因为大型企业数据量庞大,可能有几十数百的数据源,成千上万的数据库或者应用系统表需要被集成。抛开这些问题,业务部门也开始开放式地思考,什么样的数据能够辅助决策,创新业务,能够随时随心快速提取使用数据就变成一种刚需。此时,需要一种非常灵活的数据集成融合服务,它应当可以支持各种形式的数据源,包括但不限于各种数据库管理系统,同时,需要对所有数据源提供实时(低延迟)和定时(高延迟)两种采集模式,并可以自由组合这两种模式,通过批流一体的方式快速帮助业务用户满足快速取数的时效性要求。
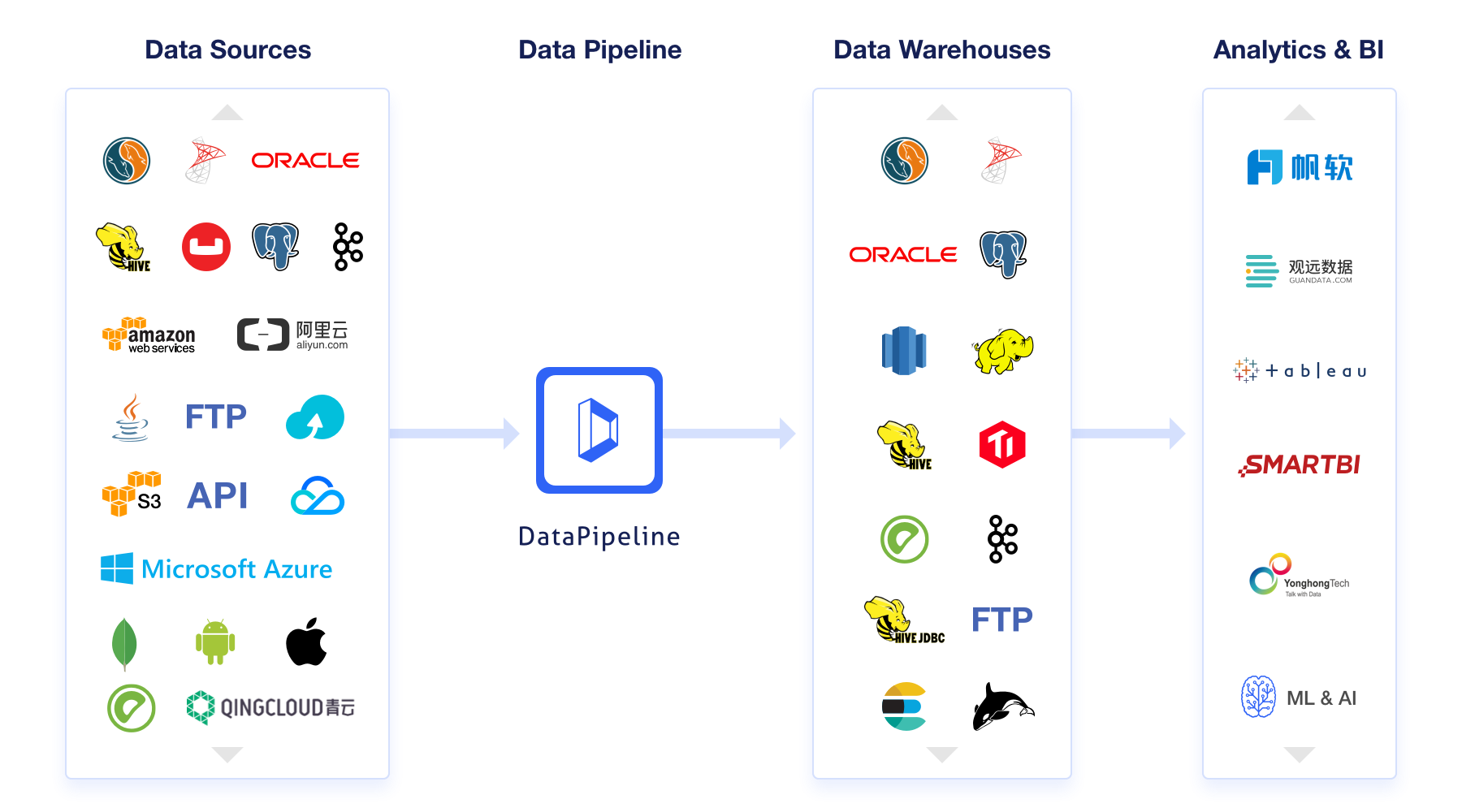
四、业务数据自动化监控和异常检测将成为有效的数据质量管理方式
Gartner2019年提出数据体系的最新趋势为“Augmented Data Management增强数据管理”,其内涵和目标都是尽量减少数据体系工作中手工的部分,利用AI算法来提高自动化,智能化,让企业将有限的资源投入到更有价值的工作中。为此,如何帮助数据部门全身心地投入到对于自动化、智能化数据科技的实践中,以最快地速度满足数据多样性、动态性、质量监控、系统稳定性的底层技术需求,是数据融合服务商一直努力的方向。
目前,随着企业拥有的实时数据应用越来越多以及人工制定规则的局限性和滞后性,过去的数据质量方案价值每况愈下,企业在摸索新的行之有效的数据质量管理方式。
2020年,在线机器学习的思路将更多的被运用到数据融合领域。一是为了应对大量的实时数据,进行实时数据质量监测。二是从算法中自动产生比手工制定大一到两个数据量级的规则,并自适应的前置应用起来。这才可能让很多基于数据的业务(销售预测/推荐/反欺诈/采购降本等)随着变化持续产生价值、避免损失。
DataPipeline作为一家企业级批流一体数据融合服务商和解决方案提供商,目前已经成功服务了星巴克、金风科技、财通证券、龙湖地产、阳光城、喜茶、正保远程教育、邵逸夫医院等涵盖地产、金融、制造、能源、零售、教育、互联网、医疗等多家行业领先的企业客户。接下来希望能联合更多客户一起去实践、碰撞,激发大家得到更为创新的发展思路 。





